
This article aims to quickly introduce the working principle of GPU, introduce the current Julia GPU ecosystem in detail, and let readers understand how easy simple GPU programming is.

How does the GPU work?
First of all, what is a GPU?
The GPU is a massively parallel processor with thousands of parallel processing units. For example, the Tesla k80 used in this article provides 4992 parallel CUDA cores. The GPU is completely different from the CPU in terms of frequency, latency, and hardware functions, but a bit similar to a slow CPU with 4992 cores!

"Tesla K80"
The number of parallel threads that can be enabled can greatly increase the speed of the GPU, but it also makes it more difficult to use. Let's take a closer look at the shortcomings you will encounter when using this primitive power:
GPU is an independent hardware with its own memory space and different architectures. Therefore, the transfer time from RAM to GPU memory (VRAM) is very long. Even starting the kernel on the GPU (in other words, scheduling function calls) will cause a large delay. GPU time is about 10us, while CPU time is a few nanoseconds.
Without advanced wrappers, setting up the kernel can quickly become complicated
Lower accuracy is the default value, and higher accuracy calculations can easily eliminate all performance gains
GPU functions (kernels) are essentially parallel, so writing GPU kernels is at least as difficult as writing parallel CPU code, but the differences in hardware add considerable complexity
Related to the above, many algorithms cannot be ported to GPU well.
The kernel is usually written in C++/C++, which is not the best language for writing algorithms.
There is a disagreement between CUDA and OpenCL, and OpenCL is the main framework for writing low-level GPU code. Although CUDA only supports NVIDIA hardware, OpenCL supports all hardware, but it is a bit rough.
The birth of Julia is great news! It is a high-level scripting language that allows you to write the kernel and surrounding code in Julia itself, while running on most GPU hardware!
GPUArrays
Most highly parallel algorithms need to pass quite a lot of data to overcome all thread and latency overhead. Therefore, most algorithms need arrays to manage all data, which requires a good GPU array library as a key foundation.
GPUArrays.jl is the foundation of Julia. It provides an abstract array implementation dedicated to the use of primitive functions of highly parallel hardware. It contains all the functions needed to set up the GPU, start Julia GPU functions and provide some basic array algorithms.
Abstraction means that it requires concrete implementations in the form of CuArrays and CLArrays. As they inherit all the functions of GPUArrays, they all provide exactly the same interface. The only difference is when the array is allocated, which forces you to decide whether the array is on a CUDA or OpenCL device. For more information on this, please refer to the memory section.
GPUArrays helps to reduce code duplication because it allows the writing of hardware-independent GPU kernels, which can be compiled into native GPU code via CuArrays or CLArrays. Therefore, many common kernels can be shared among all packages inherited from GPUArrays.
One selection suggestion: CuArrays are only suitable for Nvidia GPUs, while CLArrays are suitable for most available GPUs. CuArrays is more stable than CLArrays and can already run on Julia 0.7. The speed difference is not obvious. I suggest trying both to see which works best.
For this article, I will choose CuArrays, because this article was written for Julia 0.7/1.0 and CLArrays is still not supported.
performance
Let's use a simple interactive code example to quickly illustrate why the calculation is transferred to the GPU. This example calculates the julia set:
1usingCuArrays,FileIO,Colors,GPUArrays,BenchmarkTools 2usingCuArrays:CuArray 3""" 4ThefunctioncalculatingtheJuliaset 5""" 6functionjuliaset(z0,maxiter) 7c=ComplexF32(-0.5,0.75) 8z=z0 9foriin1:maxiter10abs2(z)>4f0& 1)%UInt811z=z*z+c12end13returnmaxiter%UInt8#%isusedtoconvertwithoutoverflowcheck14end15range=100:50:2^1216cutimes,jltimes=Float64[],Float64[]17functionrun_bench(in,outqandwrite)18#usedotsyntaxtoapply`jusetandset20#usedotsyntax_toapply`juliaset juliaset.(in,16)21#allcallstotheGPUarescheduledasynchronous,22#soweneedtosynchronize23GPUArrays.synchronize(out)24end25#storeareferencetothelastresultsforplotting26last_jl,last_cu=nothing,nothing27forNinrange28w,h=N,N29q=[Complex/F32(r) w):-1,r=-1.5:(3.0/h):1.5)30for(times,Typ)in((cutimes,CuArray),(jltimes,Array))31#converttoArrayorCuArray-movingthecalculationtoCPU/GPU32q_converted=Typ(q )33result=Typ(zeros(UInt8,size(q)))34foriin1:10#5samplespersize35#benchmarkingmacro,allvariablesneedtobeprefixedwit h$36t=Base.@elapsedbegin37run_bench(q_converted,result)38end39globallast_jl,last_cu#we'reinlocalscope40ifresultisaCuArray41last_cu=result42else43last_jl=result44end45push!(times,t)46end47end48end4950cu_last_colormap(16 +1)52color_lookup(val,cmap)=cmap[val+1]53save("results/juliaset.png",color_lookup.(cu_jl,(cmap,)))

1usingPlots;plotly()2x=repeat(range,inner=10)3speedup=jltimes./cutimes4Plots.scatter(5log2.(x),[speedup,fill(1.0,length(speedup))],6label=["cuda" "cpu"],markersize=2,markerstrokewidth=0,7legend=:right,xlabel="2^N",ylabel="speedup"8)
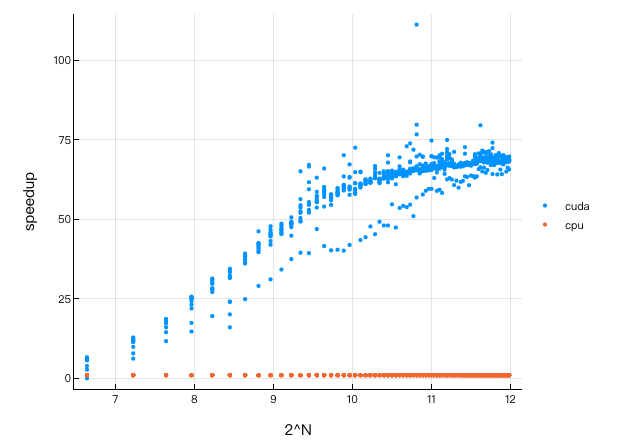
As you can see, for large arrays, a steady 60-80x speedup can be obtained by moving the calculation to the GPU. And it's very simple, just convert Julia array to GPUArray.
One might think that GPU performance is affected by dynamic languages ​​like Julia, but Julia’s GPU performance should be comparable to the original performance of CUDA or OpenCL. Tim Besard has done an excellent job of integrating the LLVM Nvidia compilation pipeline, achieving the same (sometimes better) performance as the pure CUDA C code. Tim published a very detailed blog post which explains this further [1]. The CLArrays method is a bit different. It generates OpenCL C code directly from Julia and has the same performance as OpenCL C!
In order to better understand the performance and see the comparison with the multi-threaded CPU code, I collected some benchmark tests [2].
Memory
The GPU has its own storage space, including video memory (VRAM), different caches and registers. No matter what you do, any Julia object must be transferred to the GPU before it can be used. Not all types in Julia can work on the GPU.
First let's take a look at Julia's types:
1structTest#animmutablestruct 2#thatonlycontainsotherimmutable,whichmakes 3#isbitstype(Test)==true 4x::Float32 5end 6 7#theisbitspropertyisimportant,sincethosetypescanbeused 8#withoutconstraintsontheGPU! 9@assertisbitstype(isa)==true10x=Test ,Tuple{Int,Int})#tuplesarealsoimmutable12mutablestructTest2#->mutable,isbits(Test2)==false13x::Float3214end15structTest316#containsaheapallocation/reference,notisbits17x::Vector{Float32}18y::Test2#Testap20
"Array{Test2,1}"
All these Julia types behave differently when transferred to or created on the GPU. The following table summarizes the expected results:

The creation location describes whether the object is created on the CPU and then transferred to the GPU kernel, or whether it is created on the GPU of the kernel. This table shows whether instances of the type can be created, and for transfers from the CPU to the GPU, the table also indicates whether the object is copied or passed by reference.
Garbage Collection
One big difference when using a GPU is that there is no garbage collector (GC) on the GPU. This is not a big problem, because high-performance kernels written for GPUs should not create any GC-tracked memory in the first place.
It is possible to implement GC for the GPU, but remember that each core executed is massively parallel. Creating and tracking a large amount of heap memory for each of ~1000 GPU threads will quickly destroy the performance gain, so this is actually not worth it.
As an alternative to heap allocation of arrays in the kernel, you can use GPUArrays. The GPUArray constructor will create the GPU buffer and transfer the data to VRAM. If you call Array(gpu_array), the array will be transferred back to RAM and represented as a normal Julia array. The Julia handles of these GPU arrays are tracked by Julia's GC, and if it is no longer used, the GPU memory will be released.
Therefore, stack allocation can only be used on the device and used for the remaining pre-allocated GPU buffers. Since transfers are very expensive, it is common to reuse and pre-allocate as much as possible when programming the GPU.
The GPUArray Constructors
1usingCuArrays,LinearAlgebra 2 3#GPUArrayscanbeconstructedfromallJuliaarrayscontainingisbitstypes! 4A1D=cu([1,2,3])#clforCLArrays 5A1D=fill(CuArray{Int},0,(100,))#CLArrayforCLArrays 6#Float32Float32arraybeconstructedfromallJuliaarrayscontainingisbitstypes! }(I,100,100) 8filled=fill(CuArray,77f0,(4,4,4))#3DarrayfilledwithFloat3277 9randy=rand(CuArray,Float32,42,42)#randomnumbersgeneratedontheGPU10#ThearrayconstructoralsoacceptsisbitsinceArrayCuArrayize you most of them (1:10)13#let'screateapointtypetofurtherillustratewhatcanbedone:14structPoint15x::Float3216y::Float3217end18Base.convert(::Type{Point},x::NTuple{2,Any})=Point(x[1],x[2] )19#becausewedefinedtheaboveconvertfromatupletoapoint20#[Point(2,2)]canbewrittenasPoint[(2,2)]sinceallarray21#elementswillgetconvertedtoPoint22custom_types=cu(Point[(1,2),(4,3),(2,2)])23typeof( custom_ types)
"CuArray{Point, 1}"
Array Operations
Many operations are already defined. Most importantly, GPUArrays support Julia's fusing dot broadcasting notation. This notation allows you to apply the function to each element of the array and use the return value of f to create a new array. This function is usually called a map. Broadcast means that arrays of different shapes are spread to the same shape.
It works as follows:
1x=zeros(4,4)#4x4arrayofzeros2y=zeros(4)#4elementarray3z=2#ascalar4#y's1stdimensiongetsrepeatedforthe2nddimensioninx5#andthescalarzget'srepeatedforalldimens6#thebelowiseto`broad),(+),xx7,xx,broad) +y.+z

For more explanations on how broadcasting works, you can take a look at this guide:
julia.guide/broadcasting
This means that any Julia function that runs without allocating heap memory (only the isbits type is created) can be applied to each element of the GPUArray, and multiple dot calls will be merged into one kernel call. Due to the high latency of kernel calls, this fusion is a very important optimization.
1usingCuArrays 2A=cu([1,2,3]) 3B=cu([1,2,3]) 4C=rand(CuArray,Float32,3) 5result=A.+B.-C 6test(a::T )whereT=a*convert(T,2)#converttosametypeas`a` 7 8#inplacebroadcast,writesdirectlyinto`result` 9result.=test.(A)#customfunctionwork1011#Thecoolthingisthatthiscomposeswellwithcustomtypesandcustomfunctions.12#Let'sgobacktoourPointitanddefine(13) ::Point,p2::Point)=Point(p1.x+p2.x,p1.y+p2.y)1415#nowthisworks:16custom_types=cu(Point[(1,2),(4,3), (2,2)])1718#Thisparticularexamplealsoshowsthepowerofbroadcasting:19#Nonarraytypesarebroadcastedandrepeatedforthewholelength20result=custom_types.+Ref(Point(2,2))2122#Sotheaboveisequalto(minusalltheallocations):23#thisallocateswiththeallocations):23#thisallocatevoidtheabroadpoint,which ebroad=filledCumulativeCuttinganew ,(3,))2526result==custom_types.+broadcasted
ture
GPUArrays in the real world
Let's look directly at some cool use cases.
As shown in the video below, this GPU accelerated smoke simulation is created using GPUArrays + CLArrays and can be run on GPU or CPU. The GPU version is 15 times faster:
There are more use cases, including solving differential equations, finite element simulation and solving partial differential equations.
Let's take a look at a simple machine learning example and see how to use GPUArrays:
1usingFlux,Flux.Data.MNIST,Statistics 2usingFlux:onehotbatch,onecold,crossentropy,throttle 3usingBase.Iterators:repeated,partition 4usingCuArrays 5 6#ClassifyMNISTdigitswithaconvolutionalnetwork 7 8imgs=MNIST.images() 910labels=onehotbatch(MNIST. 9)1112#Partitionintobatchesofsize1,00013train=[(cat(float.(imgs[i])...,dims=4),labels[:,i])14foriinpartition(1:60_000,1000)]1516use_gpu=true#helpertoeasilyswitchbetweengpu /cpu1718todevice(x)=use_gpu?gpu(x):x1920train=todevice.(train)2122#Preparetestset(first1,000images)23tX=cat(float.(MNIST.images(:test)[1:1000]).. .,dims=4)|>todevice24tY=onehotbatch(MNIST.labels(:test)[1:1000],0:9)|>todevice2526m=Chain(27Conv((2,2),1=>16,relu) ,28x->maxpool(x,(2,2)),29Conv((2,2),16=>8,relu),30x->maxpool(x,(2,2)),31x->reshape( x,:,size(x,4)),32Dense(288,10),softmax)|>todevice3334m(train[1][1])3536loss(x,y)=crossentropy(m(x),y)3738accuracy (x,y)=mean(onecold(m(x)).==onecold(y))3940evalcb=throttle(()->@show(accuracy(tX,tY)),10)41opt=ADAM(Flux. params(m));
1#train2fori=1:103Flux.train!(loss,train,opt,cb=evalcb)4end
accuracy(tX, tY) = 0.101
accuracy(tX, tY) = 0.888
accuracy(tX, tY) = 0.919
1usingColors,FileIO,ImageShow2N=223img=tX[:,:,1:1,N:N]4println("Predicted:",Flux.onecold(m(img)).-1)5Gray.(collect(tX[: ,:,1,N]))
Just by converting the array to GPUArrays (using gpu(array)), we can transfer the entire calculation to the GPU and get a pretty good speed increase. Thanks to Julia's complex AbstractArray infrastructure, GPUArray can be seamlessly integrated into it. Then, if you omit the conversion to GPUArray, the code will also run using normal Julia arrays-but of course this is running on the CPU. You can try this operation by changing use_gpu = true to use_gpu = false and retrying to initialize and train the cell. Comparing GPU and CPU, the CPU running time is 975 seconds, and the GPU running time is 29 seconds-an acceleration of about 33 times!
Another noteworthy benefit is that GPUArrays do not need to explicitly implement automatic differentiation in order to effectively support the back propagation of neural networks. This is because Julia's automatic differentiation library is suitable for arbitrary functions and emits code that can run efficiently on the GPU. This helps Flux to work on the GPU with a minimum of developers and enables Flux GPU to effectively support user-defined functions. Out of the box without coordination between GPUArrays + Flux is a very unique feature of Julia. See [3] for a detailed explanation.
Write GPU kernel
You can do a lot of things just by using the general abstract array interface of GPUArrays without writing any GPU kernel. However, at some point, it may be necessary to implement an algorithm that needs to run on the GPU, and it cannot be represented by a combination of general-purpose array algorithms.
The good thing is that GPUArrays reduces a lot of work through a layered approach that allows you to write low-level kernels from high-level code, similar to most OpenCL/CUDA examples. It also allows you to execute the kernel on OpenCL or CUDA devices, thereby abstracting out any differences in these frameworks.
The function that makes this possible is called gpu_call. It can be called gpu_call(kernel, A::GPUArray, args) and will call the kernel with parameters (state, args...) on the GPU. State is a back-end specific object used to implement functions such as obtaining thread indexes. GPUArray needs to be passed as the second parameter, dispatched to the correct backend and provide default values ​​of startup parameters.
Let us use gpu_call to implement a simple map kernel:
1usingGPUArrays,CuArrays 2#OverloadingtheJuliaBasemap!functionforGPUArrays 3functionBase.map!(f::Function,A::GPUArray,B::GPUArray) 4#ourfunctionthatwillrunonthegpu 5functionkernel(state,f,A,B) 6#Iflaunchparasaren'tspecified,linear_indexgetstheindex 7# intotheArraypassedassecondargumenttogpu_call(`A`) 8i=linear_index(state) 9ifi
Simply put, the above code will call the Julia function kernel length(A) times in parallel on the GPU. Each parallel call of the kernel has a thread index, which we can use to safely index into arrays A and B. If we calculate our own index instead of using linear_index, we need to ensure that no multiple threads read and write the same array position. Therefore, if we use threads to write in pure Julia, the corresponding version is as follows:
1usingBenchmarkTools 2functionthreadded_map!(f::Function,A::Array,B::Array) 3Threads.@threadsforiin1:length(A) 4A[i]=f(B[i]) 5end 6A 7end 8x,y=rand(10 ^7),rand(10^7) 9kernel(y)=(y/33f0)*(732.f0/y)10#onthecpuwithoutthreads:11single_t=@belapsedmap!($kernel,$x,$y)1213#" ontheCPUwith4threads(2realcores):14thread_t=@belapsedthreadded_map!($kernel,$x,$y)1516#ontheGPU:17xgpu,ygpu=cu(x),cu(y)18gpu_t=@belapsedbegin19map!($kernel,$xgpu,$ ygpu)20GPUArrays.synchronize($xgpu)21end22times=[single_t,thread_t,gpu_t]23speedup=maximum(times)./times24println("speedup:$speedup")25bar(["1core","2cores","gpu"] ,speedup,legend=false,fillcolor=:grey,ylabel="speedup")
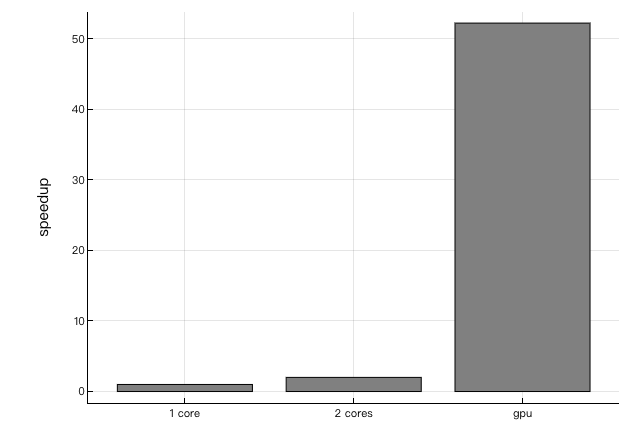
Because this function doesn't do a lot of work, we can't see a perfect extension, but the thread and GPU version still provides great speedup.
GPU is much more complicated than the thread example shows, because hardware threads are laid out in thread blocks-gpu_call is abstracted out in the simple version, but it can also be used for more complex startup configurations:
1usingCuArrays 2 3threads=(2,2) 4blocks=(2,2) 5T=fill(CuArray,(0,0),(4,4)) 6B=fill(CuArray,(0,0),(4,4 )) 7gpu_call(T,(B,T),(blocks,threads))dostate,A,B 8#thosenamesprettymuchrefertothecudanames 9b=(blockidx_x(state),blockidx_y(state))10bdim=(blockdim_x(state),blockdim_y(state ))11t=(threadidx_x(state),threadidx_y(state))12idx=(bdim.*(b.-1)).+t13A[idx...]=b14B[idx...]=t15return16end17println("Threadsindex :",T)18println("Blockindex:",B)
In the above example, you can see the more complex iterative sequence of the startup configuration. Determining the correct iteration + launch configuration is critical to achieving the best performance of the GPU.
in conclusion
Julia has made great strides in bringing composable advanced programming into the high-performance world. Now it's time to do the same with the GPU.
Hope that Julia lowers the standard for starting programming on GPU, and we can develop a scalable platform for open source GPU computing. The first success case is the realization of automatic differentiation through Julia packages. These packages are not even written for GPUs, so this gives us many reasons to believe that Julia's scalable and universal design in the field of GPU computing is successful.
ZGAR Aurora 3000 Puffs
ZGAR electronic cigarette uses high-tech R&D, food grade disposable pod device and high-quality raw material. All package designs are Original IP. Our designer team is from Hong Kong. We have very high requirements for product quality, flavors taste and packaging design. The E-liquid is imported, materials are food grade, and assembly plant is medical-grade dust-free workshops.
Our products include disposable e-cigarettes, rechargeable e-cigarettes, rechargreable disposable vape pen, and various of flavors of cigarette cartridges. From 600puffs to 5000puffs, ZGAR bar Disposable offer high-tech R&D, E-cigarette improves battery capacity, We offer various of flavors and support customization. And printing designs can be customized. We have our own professional team and competitive quotations for any OEM or ODM works.
We supply OEM rechargeable disposable vape pen,OEM disposable electronic cigarette,ODM disposable vape pen,ODM disposable electronic cigarette,OEM/ODM vape pen e-cigarette,OEM/ODM atomizer device.

Aurora 3000 Puffs,Pod System Vape,Pos Systems Touch Screen,Empty Disposable Vape Pod System,3000Puffs Pod Vape System
ZGAR INTERNATIONAL(HK)CO., LIMITED , https://www.szvape-pods.com