
Speech recognition is an abbreviation for automaTIc speech recogniTIon by machine.
Speech recognition technology is related to multidisciplinary research fields, and research results in different fields have contributed to the development of speech recognition. The difficulty of letting the machine recognize the voice is to some extent like a person with a bad foreign language listening to the voice of the outsider. It is related to the speaker, the speed of speech, the content of the speech, and the environmental conditions. The characteristics of the speech signal itself make it difficult to recognize speech. These characteristics include variability, dynamics, transients, and continuity.
The process of computer speech recognition is basically consistent with the process of human speech recognition. The current mainstream speech recognition technology is based on the basic theory of statistical pattern recognition. A complete speech recognition system can be roughly divided into three parts:
(1) Speech feature extraction: The purpose is to extract a sequence of speech features that change with time from the speech waveform.
(2) Acoustic model and pattern matching (recognition algorithm): Acoustic models usually generate acquired speech features through a learning algorithm. The input speech features are matched and compared with the acoustic model (mode) at the time of recognition to obtain the best recognition result.
(3) Language model and language processing: The language model includes a grammar network composed of recognized voice commands or a language model composed of statistical methods. Language processing can perform grammar and semantic analysis. For small vocabulary speech recognition systems, the language processing part is usually not needed.
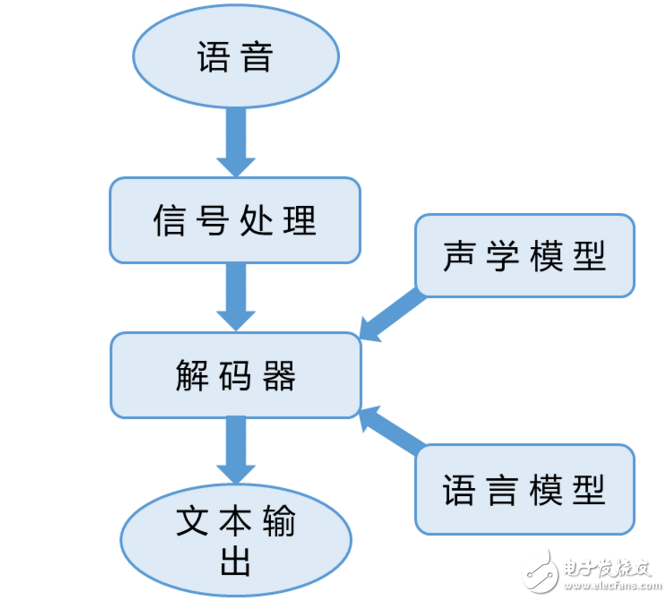
The acoustic model is the underlying model of the recognition system and is the most relevant part of the speech recognition system. The purpose of the acoustic model is to provide an efficient way to calculate the distance between the sequence of feature vectors of speech and each pronunciation template. The design of acoustic models is closely related to the features of language pronunciation. The acoustic model unit size (word pronunciation model, semi-phone model or phoneme model) has a large impact on the amount of speech training data, system recognition rate and flexibility. The size of the recognition unit must be determined according to the characteristics of different languages ​​and the size of the recognition system vocabulary. Due to various difficulties, speech recognition technology is usually constructed into different types of systems according to the restrictive requirements in use, usually including three types. One is to limit the way users talk, which can be divided into isolate-word speech recogniTIon system, connected-words speech recogniTIon system, continuous speech recognition system (continue speech recopnition) System) and impromptu spoken speech recognition system. The second is to limit the user's scope of terms. The third is to restrict the user object of the system. Using speech rate as the second information channel of the system, once the system traces the target language, it can effectively eliminate the external noise that is not synchronized with the voice information while assisting the speech recognition, so the system can obtain better recognition performance.
Image processing algorithm designThe language model is especially important for medium and large vocabulary speech recognition systems. When the classification is wrong, it can be judged and corrected according to the linguistic model, grammatical structure and semantics. In particular, some homophones must determine the meaning of the word through the context structure. Linguistic theories include semantic structure, grammatical rules, mathematical description models of language and other related aspects. The currently successful language models are usually language models using statistical grammar and language models based on regular grammatical structure commands. The grammatical structure can define the interconnection relationship between different words, which reduces the search space of the recognition system, which is beneficial to improve the recognition of the system.
The speech recognition process is actually a cognitive process. Just as people listen to speech, they don't separate the grammatical structure and semantic structure of speech and language. Because people can use these and knowledge to guide the process of understanding the language when the pronunciation is ambiguous, but for the machine, the recognition system also needs to use this knowledge, but how to effectively describe these grammar and semantics is still difficult:
(1) Small vocabulary speech recognition system: a speech recognition system including dozens of words.
(2) A medium vocabulary speech recognition system: an identification system that typically includes hundreds of words to thousands of words.
(3) Large vocabulary speech recognition system: a speech recognition system that usually includes thousands to tens of thousands of words.
These different limitations also determine the difficulty of the speech recognition system.
Organize your cabling
- Organizes all types of cables
- Ideal for network Patch Panel cabling
- Finger duct design allows easy cable organization
- Cable pass-through holes in the back of the duct
- Only set up 1U rack
- Work with threaded, round and square hole racks
- EIA 19" RACK standard compliable
- Including screws and mounting hardware
Metal Cable Management,1U Metal cable management,stainless steel cable management,metal cable tie mount
NINGBO UONICORE ELECTRONICS CO., LTD , https://www.uniconmelectronics.com