
Deep learning promotes the rapid development of many fields such as computer vision and natural language processing. In today's AI fever and talent shortage, mastering deep learning has become an indispensable skill in the research and application of AI. Li Mu, the chief scientist from Amazon, will use the classical problem of computer vision, image classification, as an example to teach everyone to build a deep neural network model from 0 to 1. For beginners faced with many questions, provide a complete introduction and code demonstrations from the environment settings, data processing, model training, effect tuning, including common methods to make the model quickly get good results - migration learning. Let everyone have a panoramic and basic understanding.
In the era of deep learning, the deepening of the Internet has made the dependence on the scale of training data sets even more successful. Large-scale datasets that are more successful in academia generally revolve around basic general cognitive problems, and are far away from the everyday somatosensory application scenarios. Fashion is closely related to people's daily life, but a large amount of content in the industry still relies on manual editing. It is an interesting and useful topic for the machine to recognize fashion by introducing artificial intelligence technology to increase efficiency.
Recently, the Alibaba Image and Beauty team and the Department of Textiles and Clothing of the Hong Kong Polytechnic University jointly organized the 2018 FashionAI Global Challenge. The FashionAI data set opened in the competition was the first large-scale high-quality product around the “clothes†in clothing, clothing, housing, and housing. data set. The dataset contains image data for eight different costumes. One of the contestants' tasks is to design an algorithm to make accurate judgments on the attributes of the clothes in the image. For example, there are six kinds of skirts, including invisible, short skirts, mid-skirts, seven-skirts, nine-skirts, and long skirts. We can regard it as a classic image classification problem and solve it through a convolutional neural network.
The image data used in the FashionAI data set is entirely derived from the e-commerce real scenes, and it portrays the challenges that the model will encounter in real-world scenarios. The models trained on the Fashoin AI dataset have both academic research value and practical application in the future to help identify professional design elements on apparel. For computer vision researchers, it is a good choice.
This article will use MXNet to explain the method. MXNet is an easy-to-install open-source deep learning tool. It provides a python interface gluon, which enables everyone to quickly build a neural network and conduct effective training. Next, we will use the skirt task in the game as an example to show us how to use gluon to start from scratch and design a simple and effective convolutional neural network algorithm.

Amazon chief scientist Li Mu
Environmental configuration
System Configuration
For deep learning training, it is important to use GPU acceleration training. Although the amount of data in this competition is not large, the use of CPU alone may still allow a model training to take a few days! Therefore, we recommend that you use at least one GPU for training. There are no GPU students, you can refer to the following two options:
According to their own budget and needs to start (the young people's) GPU. We wrote a GPU Buying Guide [1] for everyone to buy.
For this game, Amazon Cloud's GPU server was rented. We wrote an AWS running tutorial [2] to help you configure your own cloud server.
After the hardware and system are configured, we need to install CUDA and CUDNN from Nvidia to actually connect our code to the GPU hardware. This part of the installation is relatively easy, you can refer to the guidance of this section [3].
If you choose to use Amazon Cloud Server, then we recommend choosing the Deep Learning AMI when selecting the system image. This image has already configured the environment related to GPU training (CUDA, CUDNN) and does not need to do other configurations.
Install MXNet
After configuring the environment, we can install MXNet. There are many ways to install MXNet. If you want to install a GPU version for python on a Linux system, you only need to execute:

That's it. If CUDA 8.0 is installed in the system, the code can be changed to the corresponding mxnet-cu80. If there are students who want to use other language interfaces or operating systems, or if they compile their own from source code, they can find the installation steps that suit their own situation in the official installation instructions [4]. In the next tutorial, we use MXNet's python interface gluon to get everyone started.
data processing
data collection
First, we create a new data folder in the current directory, and then download the warm-up data set, training data set, and test data set from the official website to data and unzip it. The game's data can be obtained from the official website of the competition [5], but the students can only download the Tianchi account and register for the game. There are three main data sets:
fashionAI_attributes_train_20180222.tar is the main training data containing the marked training images of eight tasks. In this tutorial we only use one of the skirt tasks to demonstrate.
fashionAI_attributes_test_a_20180222.tar is the prediction data, which contains the untagged training images of eight tasks. Our purpose is to train the model and give the classification prediction on this data.
Warm_up_train_20180201.tar is warm-up data, which contains a skirt training set image that does not overlap with the training set. It is an important supplement to the training data. Before proceeding further, please confirm the current directory structure is this:

Note: The downloaded data will occupy approximately 8G of hard disk space before decompression and after decompression. In the following data we will copy the data into a more convenient directory structure, so please reserve enough hard disk space.
Because the image data set is usually large, gluon does not read all pictures into memory at one time, but constantly reads the picture files on the hard disk during training. Ask the qualified students to put the picture on the SSD. This will prevent the data reading from becoming a bottleneck, which will greatly increase the training speed.
First of all, we create a new directory under data data train_valid, as a directory of all the data after collation.

One of the reasons we chose to use skirt data is that both the warm-up data and the training data provide its training pictures, which enables us to have more abundant training resources. Below we will separately from the markup file of the training data for warm-up data:
Read the path and label of each picture
Put this picture into its corresponding directory under the data/train_valid directory by its tag
Use the top 90% of the data for training and the latter 10% for verification
The first step is to read the path and label of the training image.
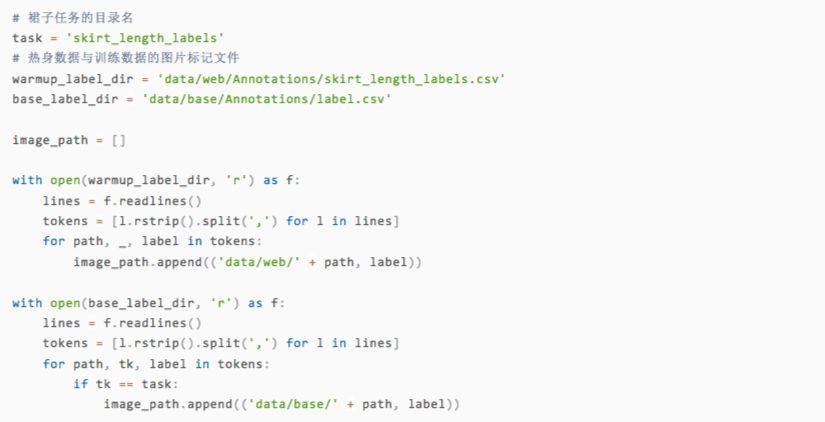
Let's check the data read in. The image_path should consist of the path and the corresponding label of the image, where the label is a string of n and y, and the position where the letter y appears is the type corresponding to the image.



It can be seen that the skirt in this picture is a long skirt. Corresponding to the official description, it can be found that it matches the mark. Next, we are ready to catalog the training set and test set, as well as subdirectories for the six skirt categories.
The running directory structure is as follows:
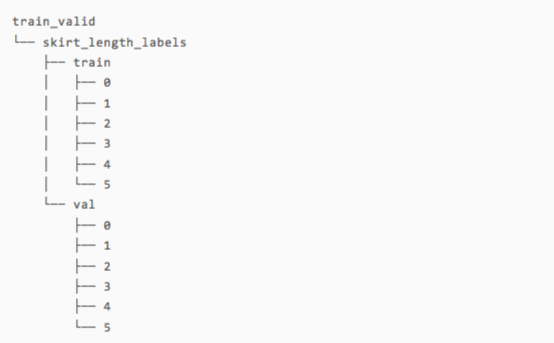
To handle other types of clothing, simply specify the task variable as the corresponding dress type name. Finally, we copy the pictures into their respective directories. It should be noted that here we deliberately randomly disrupt the order of the pictures to prevent the unevenness of the training set and the test set.

Transfer learning
After the data is ready, we can begin to design the algorithm.
The identification of clothing can be seen as a classical problem in computer vision: picture classification. A typical example is the ImageNet dataset and the ILSVRC competition, where players are required to accurately classify algorithms for more than 14 million pictures belonging to 1000 categories. In the clothing attribute contest, we can think that different attributes of clothing belong to different categories, so we can refer to the winning algorithm in ImageNet to compete.
In the preliminary stage, the organizer provided about 10,000 pictures for each type of clothing for training. This amount of data is not enough to allow us to train a great deep learning model from scratch. So we can use the idea of ​​migration learning to start from a model that has been trained on the ImageNet data set and transform it into a more “clothing†model. As shown in the figure below, on the left is a network trained on the ImageNet data set, and on the right is the network we are going to use for entry. The two main network structures are the same, so we can copy the main network weights. Since the number of classifications and meanings of the two networks in the output layer are not the same, we need to redefine the output layer and initialize it randomly.
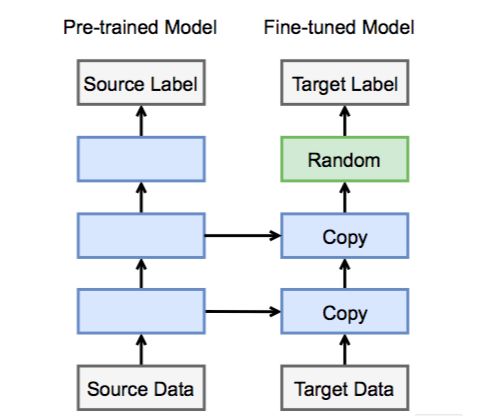
In the ImageNet data set, we mainly use convolutional neural networks, and in the past few years there have been many different network architectures. The gluon official has provided many different pre-trained convolutional neural network models. In this game, we choose the better resnet50_v2 model as the starting point for the training. A more detailed introduction to migration learning can be found in Fine-tuning in Chinese tutorials for gluon: A tutorial on migrating learning through tweaking [6].
First of all, we are ready to use the environment.

Below we can import the pre-trained resnet50_v2 model in one sentence. If you are importing the model for the first time, the code will need a little time to download the pre-trained model.

The model output trained on ImageNet is 1000-dimensional and we need to define a new resnet50_v2 network, where
The weight before the output layer is pre-trained
The output is 6-dimensional, and the weight of the output layer is initialized randomly
After that, we can choose to save the network on the CPU or GPU according to the specific machine environment.
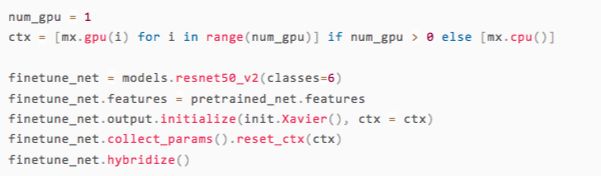
In the last line of the above code, we call hybridize, which is one of the main features of glon. It can be used to implement most of the operations in symbolic programming constructs. At the same time, it also guarantees the speed of operation. A more detailed introduction to hybridize can be found in the Hybridize Chinese tutorial: Faster and Better Porting [7] section.
Next we define several helper functions, which are
Calculate AveragePrecision, the official result evaluation criteria.
Training set and verification set image augmentation function.
The function evaluated on the test set after each round of training
For a more detailed introduction to the picture enhancement, please refer to the section of Picture Enhancement [8] in the Chinese Tutorial.


Below we define some training parameters. Note that in migration learning, we generally think that the parameters of the entire network do not need to be greatly changed. We only need to fine-tune the training data. Therefore, our learning rate is set to a relatively small value, such as 0.001.
To facilitate the demonstration, we only cycled through two rounds of training and demonstrated the process.

Next we can read in the data. After finishing, data can be read in using interface gluon.data.DataLoader

Below we define the network's optimization algorithm and loss function. In this competition, we used random gradient descent to get better results. Classification problems generally use cross-entropy as a loss function. In addition, we also care about the accuracy of the model in addition to the mAP indicator.

Now that everything is ready, we can start training! Again, here we only do two iterations for a quick demonstration. To achieve a better training effect, remember to increase the epochs.

After the training is over, how about the effect? ​​We can directly take a few pictures of the test set and compare it with the human eye to see if the type of prediction is accurate.



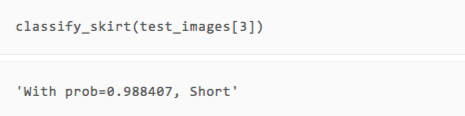

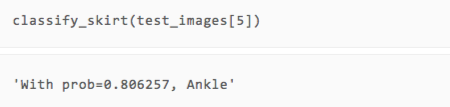

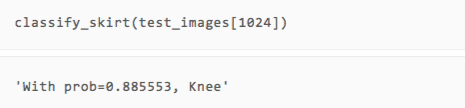

It can be seen that although there are only two rounds of training, our model has made correct predictions on the several pictures displayed.
to sum up
So far, we have shown sample code from data collation to prediction. You can start here and constantly improve the code, starting with better results. It is also recommended that you download the FashoinAI data set and use the techniques learned in this article directly. Here are some directions for improvement that you can start from:
1. Adjust the parameters, such as learning rate, batch size, training cycles, etc.
There are interactions between parameters, such as a smaller learning rate may mean more cycles.
It is recommended to select parameters with the result on the verification set
The best parameters for different data may not be the same. It is recommended to select the optimal parameters for each task.
2. Select the model. In addition to the ResNet model, gluon offers many other popular convolutional neural network models that can be selected from official documents based on their performance on ImageNet.
In the case of limited computing resources, consider using a model that occupies less memory and calculates faster.
3. More comprehensive picture expansion can consider adding more picture operations during training. The image.CreateAugmenter function has a lot of other parameters, so try out the effects separately.
In the prediction, the prediction pictures are cut/fine-tuned separately and predicted separately. Finally, the average prediction value is the final answer, and more robust results can be obtained.
Special thanks to: Author/Amazon Director Scientist Li Mu
The Screen Protector has a self-healing technology that can automatically eliminate small scratches on the Protective Film within 24 hours. Significantly reduce dust, oil stains and fingerprint smudges, anti-scratch.
The Screen Protection Film is very suitable for curved or flat screens. The Soft Hydrogel Film perfectly matches the contour of your device. Will not affect any functions of the phone.
The Ultra-Thin Protective Film with a thickness of only 0.14mm uses 100% touch screen adaptive screen touch screen technology, complete touch screen response, high-tech technology makes the screen touch to achieve zero delay, ultra-thin material brings you "realism".
The Protection Film has excellent clarity and incredible toughness, providing a high level of clarity and a glass-like surface, highlighting the sharpness of the most advanced smartphone display images and bright colors.
If you want to know more about Self Repair Screen Protector products, please click the product details to view the parameters, models, pictures, prices and other information about Self Repair Screen Protector.
Whether you are a group or an individual, we will try our best to provide you with accurate and comprehensive information about the Self Repair Screen Protector!
Self-healing Protective Film, Self-repairing Screen Protector,Self-healing Screen Protector, Self-Healing Hydrogel Film,Hydrogel Film Screen Protector
Shenzhen Jianjiantong Technology Co., Ltd. , https://www.jjtbackskin.com